|
|
Cliente/servidor
|
sistemas
de archivos convencionales
|
|
características
|
|
·
Cada aplicación está separada de las demás aplicaciones
y los datos para cada uno se localizan en diferentes archivos lógicos
·
Es probable que la estructura sea simple, sobre todo
una estructura de archivo plano o lineal, similar a la que se encuentra en
una cinta magnética.
·
No existen, los datos relacionados no se extraen siguiendo
ligas de un registro a otro.
·
Sólo se usa el sistema
operativo y el software de sistemas normales
|
|
ventajas
|
|
|
|
Desventajas
|
|
.
|
viernes, 20 de febrero de 2015
actividad #8
martes, 10 de febrero de 2015
actividad #7
Actividad #7
Arquitecturas
de BDD
Arquitecturas de memoria compartida. Consisten de
diversos procesadores los cuales accedan una misma memoria y un misma unidad de
almacenamiento (uno o varios discos). Algunos ejemplos de este tipo son las
computadoras Sequent Encore y los mainframes IBM4090 y Bull DPS8.

Arquitecturas de disco compartido. Consiste de diversos
procesadores cada uno de ellos con su memoria local pero compartiendo una misma
unidad de almacenamiento (uno o varios discos). Ejemplos de estas arquitecturas
son los cluster de Digital, y los modelos IMS/VS Data Sharing de IBM

Arquitecturas nada compartido. Consiste de diversos
procesadores cada uno con su propia memoria y su propia unidad de almacenamiento.
Aquí se tienen los clusters de estaciones de trabajo, las computadoras Intel
Paragon, NCR 3600 y 3700 e IBM
SP2

ARQUITECTURA
ANSI/SPARC

La
arquitectura ANSI / SPARC se divide en 3 niveles:
1. EL NIVEL INTERNO. Es
el que se ocupa de la forma como se almacenan físicamente los datos.
2. EL NIVEL EXTERNO. Es
el que se ocupa de la forma como los usuarios individuales perciben los datos.
3. EL NIVEL CONCEPTUAL. Es
un nivel de mediación entre los otros dos, es decir define las estructuras de
almacenamientos el Administrador de Base de Datos.
No existe un equivalente de una arquitectura estándar para
sistemas de manejo de basesb de datos distribuidas, cada sistema ha adoptado su
propia arquitectura.
Se debe definir un modelo de referencia para un esquema
de estandarización en bases de datos distribuidas, cuyo propósito es dividir el
trabajo en piezas y esas piezas se relacionan unas con otras. Se sigue los
siguientes enfoques:
1. Basado en componentes. Se
definen las componentes del sistema junto con las relaciones entre ellas.
2. Basado en funciones. Se
identifican las diferentes clases de usuarios junto con la funcionalidad que el
sistema ofrecerá para cada clase.
3. Basado en datos. Se
identifican los diferentes tipos de descripción de datos y se especifica un
marco de trabajo arquitectural el cual define las unidades funcionales que
realizarán y/o usarán los datos de acuerdo con las diferentes vistas. Este es
el enfoque seguido por el modelo ANSI/SPARC.
Los sistemas de datos distribuidos están divididos en dos
clases:
1. Sistemas de manejo de bases de datos distribuidos
homogéneos
2. Sistemas de manejo de bases de datos distribuidos
heterogéneos
ARQUITECTURA DE UN SISTEMA DE MANEJO
DE BASES DE DATOS DISTRIBUIDOS HOMOGÉNEOS

Los sistemas homogéneos se parece a un sistema
centralizado, a diferencia que estos sus datos se distribuyen en varios sitios
comunicados por la red. No existen usuarios locales y todos ellos acceden a la
base de datos a través de una interfaz global.
Para manejar los aspectos de la distribución, se deben
agregar dos niveles a la arquitectura estándar ANSI-SPARC, de la siguiente
manera, como se muestra en la Figura
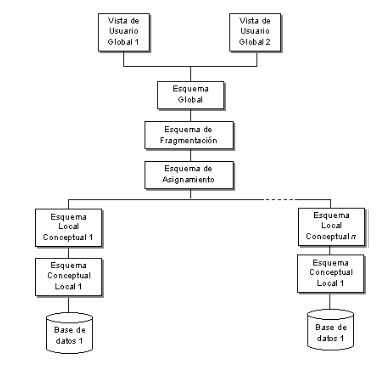
El esquema de fragmentación describe
la forma en que las relaciones globales se dividen entre las bases de datos
locales.
El esquema de asignación especifica
el lugar en el cual cada fragmento es almacenado. De aquí, los fragmentos
pueden migrar de un sitio a otro en respuesta a cambios en los patrones de
acceso.
ARQUITECTURA
DE UN SISTEMA DE MANEJO DE BASES DE DATOS DISTRIBUIDOS HETEROGÉNEOS

Un sistema multi-bases de datos tiene múltiples SMBDs,
que pueden ser de tipos diferentes, y múltiples bases de datos existentes.
Existen usuarios locales y globales.
FRAGMENTACIÓN
DE TABLAS EN BASES DE DATOS DISTRIBUIDAS” 8 ARQUITECTURA
BASADA EN COMPONENTES DE UN SISTEMA DE MANEJO DE BASES DE DATOS DISTRIBUIDOS

Consiste en dos partes como son: el procesador de datos y
el procesador de usuario.
• El procesador de usuario es el encargado de procesar
las solicitudes del usuario, consiste en cuatro partes: un manejador de la
interfaz con el usuario, un controlador semántico de datos, un optimizador
global de consultas y un supervisor de la ejecución global.
• El procesador de datos existe en cada nodo de la base
de datos distribuida. Utiliza un esquema local conceptual y un esquema local
interno, el procesador de datos consiste de tres partes: un procesador de consultas
locales, un manejador de recuperación de fallas locales y un procesador de
soporte para tiempo de ejecución.
ARQUITECTURA BASADA EN COMPONENTES DE UN
SISTEMA MULTI-BASES DE DATOS.

Consta de un sistema de manejo de bases datos para
usuarios globales y usuarios locales. Para comunicar el sistema global con los
sistemas locales se define una interfaz común entre componentes mediante la
cual, las operaciones globales se convierten en una o varias acciones locales.
Ventajas
de las Base de Datos Distribuidas
1. El primero son los costes de comunicación; si las
bases de datos están muy dispersas y las aplicaciones hacen amplio uso de los datos
puede resultar más económico dividir la aplicación y realizarla localmente.
2. El segundo aspecto es que cuesta menos crear un
sistema de pequeños ordenadores con la misma potencia que un único ordenador.
Descentralización.- En
un sistema centralizado/distribuido, existe un administrador que controla toda
la base de datos, por el contrario en un sistema distribuido existe un
administrador global que lleva una política general y delega algunas funciones
a administradores de cada localidad para que establezcan políticas locales y
así un trabajo eficiente.
1. Economía: Existen dos aspectos a tener en
cuenta.
2. Mejora de rendimiento: Pues los datos serán
almacenados y usados donde son generados, lo cual permitirá distribuir la complejidad
del sistema en los diferentes sitios de la red, optimizando la labor.
3. Mejora de fiabilidad y disponibilidad: La falla
de uno o varios lugares o el de un enlace de comunicación no implica la inoperatividad
total del sistema, incluso si tenemos datos duplicados puede que exista una
disponibilidad total de los servicios.
4. Crecimiento: Es más fácil acomodar el
incremento del tamaño en un sistema distribuido, porque la expansión se lleva a
cabo añadiendo poder de procesamiento y almacenamiento en la red, al añadir un
nuevo nodo.
5. Flexibilidad: Permite acceso local y remoto de
forma transparente.
6. Disponibilidad: Pueden estar los datos
duplicados con lo que varias personas pueden acceder simultáneamente de forma eficiente.
El inconveniente, el sistema administrador de base de datos debe preocuparse de
la consistencia de los mismos.
7. Control de Concurrencia: El sistema
administrador de base de datos local se encarga de manejar la concurrencia de
manera eficiente.
Inconvenientes
de las base de datos distribuidas.
1. El rendimiento que es una ventaja podría verse
contradicho, por la naturaleza de la carga de trabajo, pues un nodo puede verse
abrumado, por las estrategias utilizadas de concurrencia y de fallos, y el
acceso local a los datos. Se puede dar esta situación cuando la carga de
trabajo requiere un gran número de actualizaciones concurrentes sobre datos
duplicados y que deben estar distribuidos.
2. La confiabilidad de los sistemas distribuidos, esta
entre dicha, puesto que, en este tipo de base de datos existen muchos factores a
tomar en cuanta como: La confiabilidad de los ordenadores, de la red, del
sistema de gestión de base de datos distribuida, de las transacciones y de las
tazas de error de la carga de trabajo.
3. La mayor complejidad, juega en contra de este tipo de
sistemas, pues muchas veces se traduce en altos gastos de construcción y mantenimiento.
Esto se da por la gran cantidad de componentes hardware, muchas cosas que
aprender, y muchas aplicaciones susceptibles de fallar. Por ejemplo, el control
de concurrencia y recuperación de fallos, requiere de personal muy
especializado y por tal costoso.
4. El procesamiento de base de datos distribuida es
difícil de controlar, pues estos procesos muchas veces se llevan a cabo en las
áreas de trabajo de los usuarios, e incluso el acceso físico no es controlado,
lo que genera una falta de seguridad de los datos.
lunes, 9 de febrero de 2015
actividad #6
Actividad #6
Uso de las BDD en diversos sectores productivos
En este mundo modernizado existen una gran cantidad de
empresas que crecen y compiten día a día así que se han visto envueltas en la
necesidad de utilizar una base de datos distribuida para la administración de
su información, una gran cantidad de empresas que están en constante
crecimiento se ven forzadas en crear sucursales así que como anteriormente se
había mencionado utilizan BDD para compartir información a distancias y de
manera confiable gracias a que su información se encuentra dividida en
diferentes equipos. Un ejemplo de sectores que utilizan BDD puede ser:
·
bancos
·
escuelas
·
Cualquier organización
que tiene una estructura descentralizada.
·
Casos típicos de lo anterior son: organismos
gubernamentales y/o de servicio público.
·
La industria de la manufactura,
particularmente, aquella con plantas múltiples.
·
Aplicaciones de control y comando militar.
·
aerolíneas.
·
Cadenas hoteleras.
·
Servicios financieros
Transparencia y Autonomía
En un sistema de base de
datos distribuida es esencial que el sistema reduzca al mínimo la necesidad de
que el usuario se dé cuenta de cómo está almacenada una relación, un sistema
puede ocultar los detalles de la distribución de la información en la red. Esto
se denomina transparencia de la red. La transparencia de la red se relaciona,
en algún modo, a la autonomía local. La transparencia de la red es el grado
hasta el cual los usuarios del sistema pueden ignorar los detalles del diseño
distribuido. La autonomía local es el grado hasta el cual el diseñador o
administrador de una localidad pueden ser independientes del resto del sistema distribuido.
Transparencia de la
repetición y la fragmentación
No es conveniente requerir
que los usuarios hagan referencia a una copia específica de un elemento de
información. El sistema debe ser el que determine a qué copia debe acceder
cuando se le solicite su lectura, y debe modificar todas las copias cuando se
produzca una petición de escritura.
Cuando se solicita un
dato, no es necesario especificar la copia. El sistema utiliza una
tabla-catálogo para determinar cuáles son todas las copias de ese dato.
De manera similar, no debe
exigirse a los usuarios que sepan cómo está fragmentado un elemento de
información. Es posible que los fragmentos verticales contengan id-tuplas, que
representan direcciones de tuplas. Los fragmentos horizontales pueden haberse
obtenido por predicados de selección complejos. Por tanto, un sistema de bases
de datos distribuido debe permitir las consultas que se hagan en términos de
elementos de información sin fragmentar. Esto no presenta problemas graves, ya
que siempre es posible reconstruir el elemento de información original a partir
de sus fragmentos. Sin embargo, este proceso puede ser ineficiente.
Transparencia de
localización
Si el sistema es
transparente en cuanto a repetición y fragmentación, se ocultará al usuario
gran parte del esquema de la base de datos distribuida. Sin embargo, el
componente de los nombres que identifican a la localidad obliga al usuario a
darse cuenta del hecho de que cl sistema está distribuido.
La transparencia de
localización se logra creando un conjunto de seudónimos o alias para cada
usuario. Así, el usuario puede referirse a los datos usando nombres sencillos
que el sistema traduce a nombres completos.
Con el uso de seudónimos,
no será necesario que el usuario conozca la localización física de un dato.
Además, el administrador de la base de datos puede cambiar un dato de una
localidad a otra sin afectar a los usuarios.
Transparencia y
actualizaciones
De alguna forma es más
difícil hacer transparente la base de datos para usuarios que la actualizan que
para aquellos que sólo leen datos. El problema principal es asegurarse de que
se actualizan todas las copias de un dato y también los fragmentos afectados.
En el caso más general, el
problema de actualización de información repetida y fragmentada está
relacionado con el problema de actualización de vistas.
Grado de Fragmentación
Cuando se va a fragmentar
una base de datos deberíamos sopesar qué grado de fragmentación va a alcanzar,
ya que éste será un factor que influirá notablemente en el desarrollo de la
ejecución de las consultas. El grado de fragmentación puede variar desde una
ausencia de la división, considerando a las relaciones unidades de
fragmentación; o bien, fragmentar a un grado en el cada tupla o atributo forme
un fragmento. Ante estos dos casos extremos, evidentemente se ha de buscar un
compromiso intermedio, el cual debería establecerse sobre las características
de las aplicaciones que hacen uso de la base de datos. Dichas características
se podrán formalizar en una serie de parámetros. De acuerdo con sus valores, se
podrá establecer el grado de fragmentación del banco de datos.
Reglas de corrección de la
fragmentación
A continuación se enuncian
las tres reglas que se han de cumplir durante el proceso de fragmentación, las
cuales asegurarán la ausencia de cambios semánticos en la base de datos durante
el proceso.
· Disyunción. Si una relación R se
descompone horizontalmente en una serie de fragmentos R1, R2, ..., Rn,
y un elemento de datos di se encuentra en algún fragmento Rj,
entonces no se encuentra en otro fragmento Rk (kj).
Esta regla asegura que los fragmentos horizontales sean disjuntos. Si una
relación R se descompone verticalmente, sus atributos
primarios clave normalmente se repiten en todos sus fragmentos.
· Compleción. Si una relación R se
descompone en una serie de fragmentos R1, R2, ..., Rn, cada
elemento de datos que pueda encontrarse en R deberá poder
encontrarse en uno o varios fragmentos Ri. Esta propiedad
extremadamente importante asegura que los datos de la relación global se proyectan
sobre los fragmentos sin pérdida alguna. Tenga en cuenta que en el caso
horizontal el elemento de datos, normalmente, es una tupla, mientras que en el
caso vertical es un atributo.
· Reconstrucción. Si una relación R se
descompone en una serie de fragmentos R1, R2, ..., Rn, puede
definirse una operador relacional tal que el operador será diferente
dependiendo de las diferentes formas de fragmentación. La reconstrucción de la
relación a partir de sus fragmentos asegura la preservación de las restricciones
definidas sobre los datos en forma de dependencias.
Fragmentación Vertical:
El objetivo de la
fragmentación vertical consiste en dividir la relación en un conjunto de
relaciones más pequeñas tal que algunas de las aplicaciones de usuario sólo
hagan uso de un fragmento. Sobre este marco, una fragmentación óptima es
aquella que produce un esquema de división que minimiza el tiempo de ejecución
de las aplicaciones que emplean esos fragmentos.
Fragmentación Horizontal
Como se ha explicada
anteriormente, la fragmentación horizontal se realiza sobre las tuplas de la
relación. Cada fragmento será un subconjunto de las tuplas de la relación.
Existen dos variantes de la fragmentación horizontal: la primaria y la
derivada. La fragmentación horizontal primaria de una relación se desarrolla
empleando los predicados definidos en esa relación. Por el contrario, la
fragmentación horizontal derivada consiste en dividir una relación partiendo de
los predicados definidos sobre alguna otra.
Fragmentación mixta o
híbrida:
En muchos casos la
fragmentación vertical u horizontal del esquema de la base de datos no será
suficiente para satisfacer los requisitos de las aplicaciones. Como ya se citó
al comienzo de este documento podemos combinar ambas, utilizando por ello la
denominada fragmentación mixta. Cuando al proceso de fragmentación vertical le
sigue una horizontal, es decir, se fragmentan horizontalmente los fragmentos
verticales resultantes, se habla de la fragmentación mixta HV
jueves, 5 de febrero de 2015
Actividad #5
Tipos
de arquitectura
Centralizado
La
arquitectura centralizada es la más clásica. En ella, el SGBD está implantado en
una sola plataforma u ordenador desde donde se gestiona directamente, de modo
centralizado, la totalidad de los recursos. Se basa en tecnologías sencillas, muy
experimentadas y de gran robustez. También son aquellos que se ejecutan en un
único sistema informático sin interaccionar con ninguna otra computadora.
Características de las bases de datos centralizadas.
- Se almacena completamente en una
localidad central.
- No posee múltiples elementos de
procesamiento ni mecanismos de intercomunicación como las bases de datos
distribuidas.
- Los componentes de las bases de
datos centralizadas son: los datos, el software de gestión de bases de
datos y los dispositivos de almacenamiento secundario asociados.
- El problema de seguridad es fácil
de manejar en estos sistemas de bases de datos.
Cliente/servidor
Es un modelo
para el desarrollo de sistemas de información en el que las transacciones se
dividen en procesos independientes que cooperan entre sí para intercambiar
información, servicios o recursos. Se denomina cliente al proceso que inicia el
diálogo o solicita los recursos y servidor al proceso que responde a las
solicitudes.
Cada cliente
tiene un servidor directo al cual hace sus peticiones. La comunicación entre
los servidores ejecuta las transacciones y peticiones de los usuarios y esta es
transparente para ellos.
Entre las
principales características de la arquitectura cliente/servidor se pueden
destacar las siguientes:
- El servidor presenta a todos sus
clientes una interfaz única y bien definida.
- El cliente no necesita conocer la
lógica del servidor, sólo su interfaz externa.
- El cliente no depende de la
ubicación física del servidor, ni del tipo de equipo físico en el que se
encuentra, ni de su sistema operativo.
- Los cambios en el servidor
implican pocos o ningún cambio en el cliente.
Esta
arquitectura se puede clasificar en cinco niveles, según las funciones que
asumen el cliente y el servidor:
Primer nivel:
el cliente
asume parte de las funciones de presentación de la aplicación, ya que en el servidor aún hay programas que
se dedican a ese tipo de tareas. Dicha distribución se realiza mediante el uso
de productos para el "maquillaje" de las pantallas del mainframe3.
Esta técnica no exige el cambio en las aplicaciones orientadas a terminales,
pero dificulta su mantenimiento. Además, el servidor ejecuta todos los procesos
y almacena la totalidad de los datos
Segundo
nivel:
la aplicación
está soportada directamente por el servidor, excepto la presentación que es
totalmente remota y reside en el cliente. Los terminales del cliente soportan
la captura de datos, incluyendo una validación parcial de los mismos y una
presentación de las consultas
Tercer nivel:
La lógica de los procesos se divide entre los
distintos componentes del cliente y del servidor. El diseñador de la aplicación
debe definir los servicios y las interfaces del sistema de información de forma
que los papeles de cliente y servidor sean intercambiables, excepto en el
control de los datos que es responsabilidad exclusiva del servidor. En este
tipo de situaciones se dice que hay un proceso distribuido o cooperativo.
Cuarto nivel:
El cliente
realiza tanto las funciones de presentación como los procesos. Por su parte, el
servidor almacena y gestiona los datos que permanecen en una base de datos
centralizada. En esta situación se dice que hay una gestión de datos remota.
Quinto nivel:
El reparto de
tareas es como en el anterior y además el gestor de base de datos divide sus
componentes entre el cliente y el servidor. Las interfaces entre ambos están
dentro de las funciones del gestor de datos y, por lo tanto, no tienen impacto
en el desarrollo de las aplicaciones. En este nivel se da lo que se conoce como
bases de datos distribuidas.
TIPOS DE ARQUITECTURA CLIENTE-SERVIDOR:
ARQUITECTURA DE 2 CAPAS:
La arquitectura cliente/ servidor tradicional es una solución de 2
capas. La arquitectura de 2 capas consta de tres componentes distribuidos en
dos capas: cliente (solicitante de servicios) y servidor (proveedor de
servicios). Los tres componentes son:
- Interfaz de usuario.
- Gestión del procesamiento.
- Gestión de la base de datos.
Hay 2 tipos de arquitecturas cliente servidor de dos capas:
·
Clientes obesos (thick clients): La mayor parte de la lógica de la
aplicación (gestión del procesamiento) reside junto a la lógica de la
presentación (interfaz de usuario) en el cliente, con la porción de acceso a
datos en el servidor.
·
Clientes delgados (thin clients): solo la lógica de la
presentación reside en el cliente, con el acceso a datos y la mayoría de la
lógica de la aplicación en el servidor.
Es posible que un servidor funcione como cliente de otro servidor. Esto es
conocido como diseño de dos capas encadenado.
Limitaciones:
·
El número usuarios máximo es de 100. Más allá de este número de usuarios
se excede la capacidad de procesamiento.
·
No hay independencia entre la interfaz de usuario y los tratamientos, lo
que hace delicada la evolución de las aplicaciones.
·
Dificultad de relocalizar las capas de tratamiento consumidoras de
cálculo.
·
Reutilización delicada del programa desarrollado bajo esta arquitectura.
ARQUITECTURA DE 3 CAPAS:
La tercera capa (servidor intermedio) está entre el interfaz de usuario
(cliente) y el gestor de datos (servidor). La capa intermedia proporciona
gestión del procesamiento y en ella se ejecutan las reglas y lógica de
procesamiento. Permite cientos de usuarios (en comparación con sólo 100
usuarios de la arquitectura de 2 capas). La arquitectura de 3 capas es usada
cuando se necesita un diseño cliente / servidor que proporcione, en comparación
con la arquitectura de 2 capas, incrementar el rendimiento, flexibilidad,
mantenibilidad, reusabilidad y escalabilidad mientras se esconde la complejidad
del procesamiento distribuido al usuario.
Limitaciones:
Construir una arquitectura de 3 capas es una tarea complicada. Las
herramientas de programación que soportan el diseño de arquitecturas de 3 capas
no proporcionan todos los servicios deseados que se necesitan para soportar un
ambiente de computación distribuida. Un problema potencial en el diseño de
arquitecturas de 3 capas es que la separación de la interfaz gráfica de
usuario, la lógica de gestión de procesamiento y la lógica de datos no es
siempre obvia. Algunas lógicas de procesamiento de transacciones pueden
aparecer en las 3 capas. La ubicación de una función particular en una capa u
otra debería basarse en criterios como los siguientes:
- Facilidad
de desarrollo y comprobación.
- Facilidad
de administración.
- Escalabilidad
de los servidores.
- Funcionamiento
(incluyendo procesamiento y carga de la red).
Bases de datos distribuidas
Una Base de
Datos Distribuida (BDD) es un conjunto de múltiples bases de datos lógicamente
relacionadas las cuales se encuentran distribuidas entre diferentes sitios
interconectados por una red de comunicaciones, los cuales tienen la capacidad
de procesamiento autónomo lo cual indica que puede realizar operaciones locales
o distribuidas. Un sistema de Bases de Datos Distribuida (SBDD) es un sistema
en el cual múltiples sitios de bases de datos están ligados por un sistema de comunicaciones
de tal forma que, un usuario en cualquier sitio puede acceder los datos en
cualquier parte de la red exactamente como si los datos estuvieran.
Las
características de las bases de las bases de datos son las siguientes:
Autonomía
Local: Los sitios distribuido deben ser autónomos, es decir que todas las
operaciones en un sitio dado se controlan en ese sitio.
No dependencia de un sitio central: No debe de
haber dependencia de un sitio central para obtener un servicio.
Operación
Continua: Nunca debería apagarse para que se pueda realizar alguna función,
como añadir un nuevo sitio.
Independencia con respecto a la localización:
No debe de ser necesario que los usuarios sepan dónde están almacenados físicamente
los datos, sino que más el usuario lo debe de ver como si solo existiera un
sitio local
Independencia
con respecto a la fragmentación: La fragmentación es deseable por razones de
desempeño, los datos, pueden almacenarse en la localidad donde se utilizan con
mayor frecuencia de manera que la mayor parte de las operaciones sean sólo
locales y se reduzca el tráfico en la red.
Independencia
de réplica: Si una relación dada (es decir, un fragmento dado de una relación)
se puede presentar en el nivel físico mediante varias copias almacenadas o
réplicas, en muchos sitios distintos.
Suscribirse a:
Comentarios (Atom)