Actividad #7
Arquitecturas
de BDD
Arquitecturas de memoria compartida. Consisten de
diversos procesadores los cuales accedan una misma memoria y un misma unidad de
almacenamiento (uno o varios discos). Algunos ejemplos de este tipo son las
computadoras Sequent Encore y los mainframes IBM4090 y Bull DPS8.

Arquitecturas de disco compartido. Consiste de diversos
procesadores cada uno de ellos con su memoria local pero compartiendo una misma
unidad de almacenamiento (uno o varios discos). Ejemplos de estas arquitecturas
son los cluster de Digital, y los modelos IMS/VS Data Sharing de IBM

Arquitecturas nada compartido. Consiste de diversos
procesadores cada uno con su propia memoria y su propia unidad de almacenamiento.
Aquí se tienen los clusters de estaciones de trabajo, las computadoras Intel
Paragon, NCR 3600 y 3700 e IBM
SP2

ARQUITECTURA
ANSI/SPARC

La
arquitectura ANSI / SPARC se divide en 3 niveles:
1. EL NIVEL INTERNO. Es
el que se ocupa de la forma como se almacenan físicamente los datos.
2. EL NIVEL EXTERNO. Es
el que se ocupa de la forma como los usuarios individuales perciben los datos.
3. EL NIVEL CONCEPTUAL. Es
un nivel de mediación entre los otros dos, es decir define las estructuras de
almacenamientos el Administrador de Base de Datos.
No existe un equivalente de una arquitectura estándar para
sistemas de manejo de basesb de datos distribuidas, cada sistema ha adoptado su
propia arquitectura.
Se debe definir un modelo de referencia para un esquema
de estandarización en bases de datos distribuidas, cuyo propósito es dividir el
trabajo en piezas y esas piezas se relacionan unas con otras. Se sigue los
siguientes enfoques:
1. Basado en componentes. Se
definen las componentes del sistema junto con las relaciones entre ellas.
2. Basado en funciones. Se
identifican las diferentes clases de usuarios junto con la funcionalidad que el
sistema ofrecerá para cada clase.
3. Basado en datos. Se
identifican los diferentes tipos de descripción de datos y se especifica un
marco de trabajo arquitectural el cual define las unidades funcionales que
realizarán y/o usarán los datos de acuerdo con las diferentes vistas. Este es
el enfoque seguido por el modelo ANSI/SPARC.
Los sistemas de datos distribuidos están divididos en dos
clases:
1. Sistemas de manejo de bases de datos distribuidos
homogéneos
2. Sistemas de manejo de bases de datos distribuidos
heterogéneos
ARQUITECTURA DE UN SISTEMA DE MANEJO
DE BASES DE DATOS DISTRIBUIDOS HOMOGÉNEOS

Los sistemas homogéneos se parece a un sistema
centralizado, a diferencia que estos sus datos se distribuyen en varios sitios
comunicados por la red. No existen usuarios locales y todos ellos acceden a la
base de datos a través de una interfaz global.
Para manejar los aspectos de la distribución, se deben
agregar dos niveles a la arquitectura estándar ANSI-SPARC, de la siguiente
manera, como se muestra en la Figura
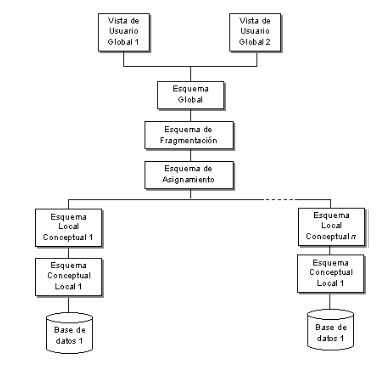
El esquema de fragmentación describe
la forma en que las relaciones globales se dividen entre las bases de datos
locales.
El esquema de asignación especifica
el lugar en el cual cada fragmento es almacenado. De aquí, los fragmentos
pueden migrar de un sitio a otro en respuesta a cambios en los patrones de
acceso.
ARQUITECTURA
DE UN SISTEMA DE MANEJO DE BASES DE DATOS DISTRIBUIDOS HETEROGÉNEOS

Un sistema multi-bases de datos tiene múltiples SMBDs,
que pueden ser de tipos diferentes, y múltiples bases de datos existentes.
Existen usuarios locales y globales.
FRAGMENTACIÓN
DE TABLAS EN BASES DE DATOS DISTRIBUIDAS” 8 ARQUITECTURA
BASADA EN COMPONENTES DE UN SISTEMA DE MANEJO DE BASES DE DATOS DISTRIBUIDOS

Consiste en dos partes como son: el procesador de datos y
el procesador de usuario.
• El procesador de usuario es el encargado de procesar
las solicitudes del usuario, consiste en cuatro partes: un manejador de la
interfaz con el usuario, un controlador semántico de datos, un optimizador
global de consultas y un supervisor de la ejecución global.
• El procesador de datos existe en cada nodo de la base
de datos distribuida. Utiliza un esquema local conceptual y un esquema local
interno, el procesador de datos consiste de tres partes: un procesador de consultas
locales, un manejador de recuperación de fallas locales y un procesador de
soporte para tiempo de ejecución.
ARQUITECTURA BASADA EN COMPONENTES DE UN
SISTEMA MULTI-BASES DE DATOS.

Consta de un sistema de manejo de bases datos para
usuarios globales y usuarios locales. Para comunicar el sistema global con los
sistemas locales se define una interfaz común entre componentes mediante la
cual, las operaciones globales se convierten en una o varias acciones locales.
Ventajas
de las Base de Datos Distribuidas
1. El primero son los costes de comunicación; si las
bases de datos están muy dispersas y las aplicaciones hacen amplio uso de los datos
puede resultar más económico dividir la aplicación y realizarla localmente.
2. El segundo aspecto es que cuesta menos crear un
sistema de pequeños ordenadores con la misma potencia que un único ordenador.
Descentralización.- En
un sistema centralizado/distribuido, existe un administrador que controla toda
la base de datos, por el contrario en un sistema distribuido existe un
administrador global que lleva una política general y delega algunas funciones
a administradores de cada localidad para que establezcan políticas locales y
así un trabajo eficiente.
1. Economía: Existen dos aspectos a tener en
cuenta.
2. Mejora de rendimiento: Pues los datos serán
almacenados y usados donde son generados, lo cual permitirá distribuir la complejidad
del sistema en los diferentes sitios de la red, optimizando la labor.
3. Mejora de fiabilidad y disponibilidad: La falla
de uno o varios lugares o el de un enlace de comunicación no implica la inoperatividad
total del sistema, incluso si tenemos datos duplicados puede que exista una
disponibilidad total de los servicios.
4. Crecimiento: Es más fácil acomodar el
incremento del tamaño en un sistema distribuido, porque la expansión se lleva a
cabo añadiendo poder de procesamiento y almacenamiento en la red, al añadir un
nuevo nodo.
5. Flexibilidad: Permite acceso local y remoto de
forma transparente.
6. Disponibilidad: Pueden estar los datos
duplicados con lo que varias personas pueden acceder simultáneamente de forma eficiente.
El inconveniente, el sistema administrador de base de datos debe preocuparse de
la consistencia de los mismos.
7. Control de Concurrencia: El sistema
administrador de base de datos local se encarga de manejar la concurrencia de
manera eficiente.
Inconvenientes
de las base de datos distribuidas.
1. El rendimiento que es una ventaja podría verse
contradicho, por la naturaleza de la carga de trabajo, pues un nodo puede verse
abrumado, por las estrategias utilizadas de concurrencia y de fallos, y el
acceso local a los datos. Se puede dar esta situación cuando la carga de
trabajo requiere un gran número de actualizaciones concurrentes sobre datos
duplicados y que deben estar distribuidos.
2. La confiabilidad de los sistemas distribuidos, esta
entre dicha, puesto que, en este tipo de base de datos existen muchos factores a
tomar en cuanta como: La confiabilidad de los ordenadores, de la red, del
sistema de gestión de base de datos distribuida, de las transacciones y de las
tazas de error de la carga de trabajo.
3. La mayor complejidad, juega en contra de este tipo de
sistemas, pues muchas veces se traduce en altos gastos de construcción y mantenimiento.
Esto se da por la gran cantidad de componentes hardware, muchas cosas que
aprender, y muchas aplicaciones susceptibles de fallar. Por ejemplo, el control
de concurrencia y recuperación de fallos, requiere de personal muy
especializado y por tal costoso.
4. El procesamiento de base de datos distribuida es
difícil de controlar, pues estos procesos muchas veces se llevan a cabo en las
áreas de trabajo de los usuarios, e incluso el acceso físico no es controlado,
lo que genera una falta de seguridad de los datos.
lol
ResponderEliminar